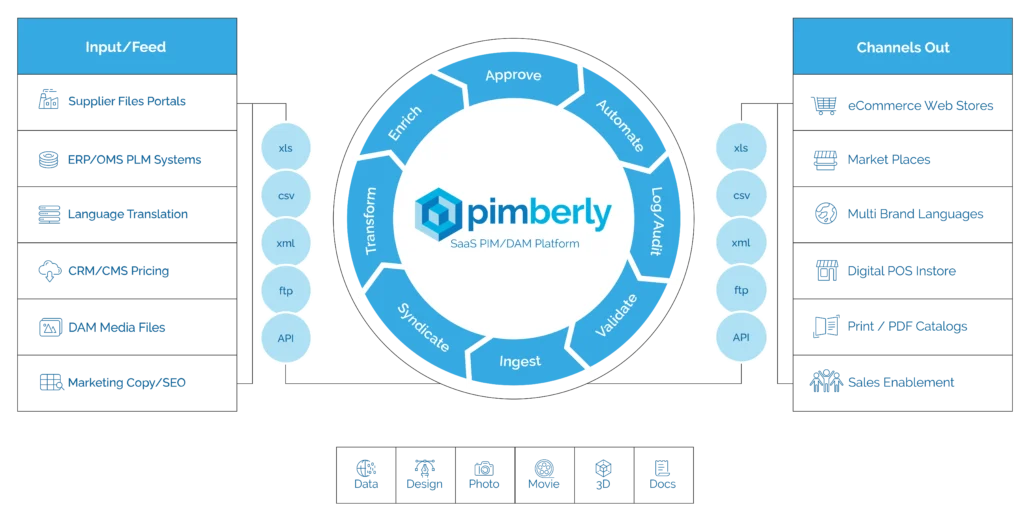
B2B organizations are under increasing pressure to do more with their product data—faster, at greater scale, and with fewer resources. As product catalogs grow, sales channels multiply, and compliance requirements tighten, many teams are discovering that traditional Product Information Management (PIM) approaches alone are no longer enough. Manual enrichment, spreadsheet-driven workflows, and legacy systems struggle to keep pace with the speed and complexity of modern commerce. This challenge has turned product data from a back-office concern into a strategic business priority.
Artificial intelligence is now reshaping how organizations address these challenges. When embedded directly into PIM workflows, AI moves beyond experimentation and delivers measurable business value. AI-powered automation can dramatically reduce the time and cost required to enrich product data, improve accuracy and consistency across channels, and unlock new revenue opportunities by accelerating product launches and enabling catalog expansion.
This whitepaper (~15,000 words) explores how AI-driven PIM transforms product data operations into a scalable growth engine. It outlines where manual and legacy approaches fall short, how AI is being applied in real-world PIM use cases today, and—most importantly—how organizations can quantify the return on investment.
For B2B leaders looking to modernize their product data strategy, the message is clear: AI in PIM is no longer a future concept—it is a proven, business-ready capability that drives measurable ROI.
Digital transformation in the B2B sector has accelerated significantly, and product data is now at the center of growth, efficiency, and customer experience. Managing product information has become increasingly important and challenging as product catalogs expand, sales channels proliferate, and compliance regulations become stricter. Spreadsheets, manual data entry, and isolated systems are not able to keep up with this speed or size.
Artificial intelligence is becoming the most important aspect that changes how Product Information Management (PIM) provides demonstrable value. When used in a strong PIM framework, AI capabilities are no longer just ideas. They are already seeing real results by automating the process of adding more information to product data, making sure that it is correct across all channels, speeding up time to market, and opening up new ways to make money. For B2B businesses, the promise is clear: AI-powered automation can cut costs, make things ten times more efficient, and let them move into new markets without having to hire more people.
Companies have already started to figure out how much this change is worth in marketplaces around the world. Companies that use AI-powered PIM solutions say that product introductions are up to 70% faster, manual enrichment time is cut by 40%, and SKU correctness is always above 98%. These benefits go beyond making operations run more smoothly. They also let catalogs grow quicker, provide better omnichannel experiences, and measurably boost revenue. As digital shoppers want more precise, localized, and accurate product information, AI guarantees that manufacturers and distributors can grow without losing accuracy or compliance.
This whitepaper talks about how AI-powered automation is changing the way PIM works. It will explain how AI may be used in businesses in simple terms, point out the models and technologies that are already available to provide value today, and talk about important issues like security, compliance, and the difference between public and private AI models. The conversation also talks about how AI may be used in the B2B product lifecycle, from hyper-personalized product experiences and channel syndication to automating the processing of safety data sheets (SDS) and getting information from old data.
The report also stresses how important it is to use what you learn in the actual world. Instead of talking about theories, it gives you ways to measure ROI, check if you’re ready to deploy, and make sure that PIM modernization fits in with your company’s goals, such as sustainability, following the rules, and going digital. Decision-makers will see clear examples of how automation can lead to quantitative results, like fewer enrichment workers, lower return rates, or faster access into new markets.
The focus of this research is the analysis of ROI. This whitepaper offers a systematic method for assessing the business case for AI in PIM by measuring savings in time, operational expenses, and SKU onboarding, along with the revenue generation resulting from quicker releases and more product visibility. There are real-world calculations, standards, and visual frameworks to help decision-makers make sure these opportunities fit with their strategic goals.
The main goal of this article is to show that AI in PIM is a technology that is already being used and is changing how businesses handle product complexity on a large scale. Businesses may gain unprecedented levels of flexibility and control over the lifespan of their product data by adding intelligence directly to PIM operations. This makes the business more responsive and data-driven, so it can quickly and accurately meet changing customer needs.
Who Should Read This Whitepaper?
This whitepaper is intended for enterprise leaders who are shaping the future of digital product management, including:
Executives in eCommerce, product, IT, and data functions
Digital transformation leaders seeking practical frameworks for AI adoption
Operations and compliance teams are responsible for product governance
Systems integrators, solution architects, and consultants building enterprise roadmaps
For this group, the promise is clear: AI in PIM is a business-ready feature that combines compliance, efficiency, and scalability. Organizations that act now will benefit the most because they will be able to get long-term returns on their investments and become leaders in a market that values speed, accuracy, and trust.
As PIM platforms evolve into intelligent ecosystems, AI becomes the critical differentiator between reactive data management and proactive data leadership. The companies that integrate these capabilities today are not only streamlining their current operations—they are laying the foundation for continuous innovation, automated compliance, and sustainable growth in an increasingly digital-first economy.
2. Introduction: The New Era of Product Data Management
2.1 The Complexity of Modern B2B Commerce
The world of enterprise B2B trade is now defined by size and speed. Product catalogs used to just include a few hundred SKUs, but now manufacturers, distributors, and retailers often have tens or even hundreds of thousands, each with its own set of variants, attributes, and compliance needs. At the same time, product data needs to move easily between more and more digital and physical channels, including eCommerce sites, worldwide marketplaces, distributors, resellers, and direct-to-customer settings. This makes things more complicated than they used to be, which puts a strain on old systems and shows their flaws.
Businesses have changed how they work since there are so many digital outlets. There are now many versions of every product, each one made to fit different language needs, regional laws, or client groups. Because of this, managing product data is no longer just something that happens in the back office; it’s now a key part of being competitive in the digital world. Companies need to make sure that all of the attributes, descriptions, images, and technical specifications are the same on hundreds of endpoints. Also, consumers want the same level of accuracy and transparency no matter where they buy, whether it’s through an enterprise procurement platform, a third-party marketplace, or a direct eCommerce gateway.
The product lifecycle used to be a straight line: make it, distribute it, and sell it. Now it’s a digital ecosystem that needs data to be constantly enriched, shared, and verified. Because of this increasing complexity, even small mistakes in data can have big effects on business, such launches that are delayed or fines from regulators. Business is moving faster, but many data procedures haven’t kept up with it.
2.2 The Challenge of Manual and Legacy PIM Workflows
Many businesses still use manual enrichment, spreadsheets, or old PIM routines to maintain product data. These methods require a lot of human effort to keep up with product descriptions, photos, specifications, translations, and compliance information. The results are easy to guess: product launches will be delayed, work will be duplicated, operational costs will go up, and the chance of mistakes will go up, which will damage confidence with customers and partners. The risks are much higher in fields where following the rules is required, such as medical equipment, building materials, or consumer electronics. A single mistake in a safety data sheet or specification might hurt your reputation, cost you money in fines, or cost you business.
This dependence on human labor also makes it hard to grow. As catalogs get bigger, even experienced teams have a hard time keeping up with all the changes that need to be made, such as adding new products, variants, or changes to the law. What used to take a few days can now take weeks of working together between departments. When data goes through more than one person, system, or file version, mistakes happen more often. Every step in the manual process adds a new point of failure.
Legacy PIM processes also lack real-time visibility. When teams work in silos, they can cause version conflicts or old product information to spread between departments and sales channels. In a world where digital shoppers base their buying choices on precise, current information, these kinds of problems are no longer acceptable. Companies risk losing not only money but also the trust of their customers, which is much harder to get back than any one sale.
2.3 Where Traditional Approaches Fall Short
Legacy systems and fragmented processes were never meant to handle the needs of today’s multichannel world. They have trouble scaling up as the number of SKUs grows, they can’t simply switch between different channel formats, and they typically don’t have the ability to add localized data or personalized product experiences. As digital customers’ expectations rise, manual methods of enrichment and validation become sluggish, expensive, and impossible to keep up with. They want accurate, real-time product information. Businesses that can’t adjust to this gap between what the market needs and what they can do are at a competitive disadvantage, miss out on income opportunities, and create bottlenecks.
Traditional approaches not only waste time, but they also stifle new ideas. When teams are stuck on data upkeep, they don’t have much time for strategic work like looking at the market, comparing themselves to competitors, or trying out new channels. PIM systems that have been around for a while were made to be stable, not flexible. They typically need help from IT for even little changes, which slows down time-to-market and makes people less likely to try new things.
Also, old systems have trouble with globalization and localization. It quickly becomes too much work to translate product data into several languages, make sure measurements are in line with local standards, and keep up with all the rules in different areas. These limits create big problems for expansion as organizations move abroad.
In the end, traditional methods have hit a wall in a time when speed, scalability, and intelligence are important. Product data management for the next generation needs to be more than just static systems; it needs to be able to think, learn, and change.
2.4 How AI is Redefining Product Information Strategies
This equation is changing because of artificial intelligence. AI makes it easier and faster to get items ready for market by automating operations that are done over and over again, such as filling in attributes, normalizing data, and managing translations. AI improves the quality and consistency of data by using validation criteria on a large scale, which helps to reduce errors and duplicates. It also lets firms personalize product data for different markets, channels, and client segments without having to recreate key information. AI shortens the time it takes to get products to market across all SKUs and channels. This means speedier launches, easier compliance, and more flexibility.
AI creates a new way of thinking about things in which product data improves itself. Machine learning models may find strange things, guess what values are missing, and automatically add to content based on what has happened in the past. Natural language models make product descriptions that are good for SEO and follow tone, style, and localization guidelines. Vision-based models can tell things like color, substance, or type of packaging immediately from pictures, so you don’t have to tag them by hand over and over again.
AI also helps organizations turn product data into strategic intelligence on a larger scale. Instead of reacting to mistakes or delays, teams may look ahead to see what will happen, guess what content will be needed, and make sure that their product data strategies match what customers do. The result is a system that not only helps with day-to-day tasks but also helps with making decisions in marketing, merchandising, and supply chain duties.
In short, AI-driven automation is more than just a way to save money; it’s changing the way businesses think about how to handle product information. Companies that want to do well in the new era of B2B commerce need to use AI in their PIM systems. This will help them expand, stay strong, and connect with customers better.
3. What Is “AI in PIM”?
3.1 Defining AI in the Context of Product Information Management
Artificial Intelligence in Product Information Management (AI in PIM) is the use of machine intelligence in areas including natural language processing, computer vision, and data extraction to improve every step of the product data lifecycle. AI in PIM is not really about replacing people; it’s about automating the boring, error-prone processes that teams have to do all the time. AI helps businesses grow quickly, deploy products more efficiently, and keep the consistency needed for global B2B commerce by taking care of the hard work of classification, enrichment, and validation.
In real life, this means using AI-powered technologies to turn unstructured data into structured attributes, automatically add to product descriptions, and check data quality in real time. AI doesn’t only work as a separate add-on; it becomes a part of the workflows of a contemporary PIM, making both operational efficiency and strategic agility better.
So, AI’s function in PIM is both tactical and strategic. On a tactical level, it gets rid of unnecessary work by turning old, manual data tasks into quick, automated, and repeatable workflows. In a strategic sense, it helps businesses use product data as a competitive advantage that can drive personalization, speed up launches, and ensure compliance at scale. AI can be used in a business setting on many types of data, such as text, images, numbers, and relationships. Natural language processing makes it easier to understand long-form specs and turn them into organized, channel-ready material. Vision AI can help you tag and sort your assets. Extraction models turn PDFs and technical drawings into data that may be used. These functions work together to make product information into a smart system that learns from every update and becomes better at being accurate and efficient all the time.
3.2 Core Capabilities of AI-Driven PIM
Natural Language Processing and Copy Generation AI language models are getting better and better at comprehending and writing text about products. They can write product descriptions that are good for SEO, pull out attributes from long-form specifications, translate information into different languages, and change the format of text to fit style and length requirements. This feature cuts down on the time needed to write and edit text while making sure that all SKUs and sales channels are consistent.
Image-Based Attribution and Classification AI can find colors, materials, patterns, and other important product features directly from pictures thanks to computer vision. AI does away with the necessity for manual categorization by tagging assets and linking them to taxonomies. Image recognition goes beyond tagging by making alt text that is accurate and making sure that product images fit accessibility and compliance criteria.
Pattern Recognition and Anomaly Detection Managing huge catalogs can often lead to problems with data quality. AI is great at finding problems, such as missing properties, contradictory requirements, or formatting that doesn’t match, before they get to downstream systems. AI may enforce set standards and suggest fixes by learning from past data. This builds trust in product information across departments and sales partners.
Intelligent Automation and Workflow Orchestration AI-driven workflows connect directly with PIM systems to sort products, add attributes, check for completeness, and send exceptions to human reviewers. This cuts down on the need for people to step in and speeds up the approval process. Automation is important because it makes sure that product data governance is followed. It does this by letting you set thresholds that balance speed and accuracy.
Large-Scale Personalization and Variant Generation Today’s B2B buyers want product experiences that are specific to their sector, area, or even job title. AI lets you develop several versions of content that are tailored to your needs, like product descriptions that are relevant to your location or industry-specific spec sheets. In the past, this kind of personalization was impossible to do on a large scale. AI now makes it possible without adding to the burden.
3.3 AI as a Co-Pilot: Shifting Human Effort from Data Entry to Strategy
Perhaps the most transformative aspect of AI in PIM is its role as a co-pilot rather than a replacement. AI takes care of boring tasks like entering data, tagging things over and over, and basic enrichment. This lets teams focus on more important things like coming up with new products, expanding into new markets, and connecting with customers. The change is from being “keepers of data” to helping things grow.
Businesses get richer, more reliable product information, and a faster time-to-market when AI is built into PIM. The result is an operational model that fits with how B2B commerce works today: data that is always correct, workflows that can grow without any problems, and teams who are free to focus on strategic goals instead of getting bogged down by administrative activities.
AI changes how teams use their time and skills in real life. Professionals can now monitor how products are doing, create assortments, and improve customer journeys instead of managing spreadsheets or checking line items. Product managers can work with marketing to make stories better instead of formatting tables. Compliance teams can focus on being ready for an audit instead of doing manual validation. Companies can keep human control where it matters most—strategy, creativity, and decision-making—by using AI as a co-pilot and automating everything else. This collaboration between human knowledge and artificial intelligence is what has changed PIM from a static data storage system to a dynamic intelligence engine that will drive the next generation of B2B business.
4. Current, Practical AI Models Powering PIM
Several AI techniques have developed sufficiently in recent years to provide tangible benefits when integrated with PIM systems. These models make product information procedures more automated, keep data safe, and make it easier to grow. This part looks at six types of AI models that are being used in PIM and important things to think about while using them.
4.1 Large Language Models (LLMs) for Product Copy and Data Enrichment
Large Language Models (LLMs) are currently quite useful for automating a lot of the “writing and rewriting” work that product teams usually have to do. In the context of PIM, LLMs have a few different jobs:
Creating descriptions and content: An LLM can make SEO-friendly, buyer-focused descriptions based on a collection of product features or technical specifications. These descriptions can be customized by length, tone, or target channel.
Extracting attributes from text: Models can read unstructured text (like spec sheets or supplier documentation) and turn it into structured attributes that PIM may use.
Translation and localization: LLMs can make several versions of descriptions that work for different regions by taking into account linguistic differences, local measurement units, and compliance terms.
Q&A / content support: Teams can use LLMs to answer questions about technical issues or attributes, which speeds up content generation and cuts down on bottlenecks.
The pros are clear: you can write quickly, keep a consistent style across thousands of SKUs, make content that is suitable for SEO, and reach people in many languages, all with very little human help.
In fact, this is similar to Pimberly’s Copy AI module, which employs natural language processing (NLP) to automatically create product copy from prompts or structured data.
LLMs also help companies make sure that their brand voice and compliance language are the same at every point of contact with a product. For example, a home remodeling company can quickly write descriptions for 5,000 SKUs in a uniform style and tone while making sure that regional compliance terms like “RoHS certified” or “REACH compliant” are automatically added. Also, businesses may make sure that the outputs match their industry’s vocabulary by fine-tuning these models on data that is relevant to that field. This will create product stories that are both technically accurate and interesting.
By linking LLMs with process triggers, PIM systems may automatically create draft copy when an SKU is made. This cuts down on time to market and human content bottlenecks by a huge amount. The outcome is a smarter, more efficient content pipeline where human review is the last step in quality control instead of the main reason for creation.
4.2 Image Recognition and Tagging for Metadata Consistency
Computer vision models are another important part of AI in PIM. These models look at pictures and get a lot of useful information from them, like color, material, pattern, style, shape, and whether or not an object is there. What they do is:
Auto-tagging visual assets with attributes that supplement textual data
Classifying images into taxonomies (e.g., interior lighting, industrial component)
Generating alt-text and accessibility metadata to support SEO and compliance
Validating that images match expected product attributes (e.g., no mismatch between claimed color in text vs image)
PIM systems make sure that metadata is more complete, filtering and searching are more reliable, and new SKUs can be added more quickly by automating the extraction of attributes from the image layer. This makes it easier to find things and cuts down on mistakes made by hand.
Image recognition now does more than just basic tagging; it can also do automated quality assurance and compliance monitoring. For instance, it can tell if a product image matches the rules of the marketplace (like Amazon’s regulation about white backgrounds) or if the packaging labels are clear for regulatory reasons. Visual models can find little differences in texture, finish, or color in clothing, furniture, or hardware. This makes sure that visual data matches product metadata before it is sent out.
Companies can achieve metadata consistency on a large scale by training models on industry-specific datasets, such as electrical components, medical supplies, or clothing. This cuts down on human classifications and speeds up the onboarding process for thousands of SKUs each month.
4.3 Domain-Specific Extraction: OCR and Structured Data Parsing
A lot of product data is still stored in old formats like PDFs, scanned datasheets, CAD drawings, or supplier catalogs. This data can be unlocked by AI models that are good at Optical Character Recognition (OCR) and structural parsing:
PDFs and data sheets: Get tables, embedded dimensions, material lists, and safety statements, and turn them into structured attribute fields.
Diagrams for technical purposes: Read labeled measurements or render attribute values from vector or raster engineering drawings.
Standardization and normalization: Change different ways of writing things (such as “30 cm × 20 cm × 10 cm” vs. “300 × 200 × 100 mm”) into common attribute forms.
This feature converts old data that would otherwise be useless into useful product information without the need for re-keying. It is especially helpful for older catalog backlogs or long-tail SKUs.
OCR and domain-aware extraction models are very useful in the industrial, chemical, and manufacturing fields, where a lot of product data comes from compliance documents or supplier PDFs. For instance, AI may pull information from safety data sheets (SDS), such as hazard statements, handling instructions, and chemical compositions, and put them straight into PIM characteristics. This makes it possible to automatically keep track of compliance and make it easy to sync with systems like ERP or eCommerce catalogs.
AI may also verify for logical coherence in extracted data when it is used with validation layers. For example, it can make sure that density numbers match volume and weight. This lets companies digitally unlock years of old product data over time, turning static archives into useful, searchable product knowledge bases that get better with each iteration.
4.4 Predictive Analytics for Pricing, Attribute Prioritization, and Content Optimization
In addition to extraction and labeling, predictive models assist businesses in sorting and improving product information. Some examples of use cases are:
Pricing suggestions: Models look at market trends, competitive prices, and patterns of demand to come up with the best prices for new or different SKUs.
Attribute prioritization: Algorithms can rank which missing qualities (such as weight, certifications, or material) are most likely to affect conversions or channel acceptability. This helps teams focus on the most important things.
Guidelines for how well content works: AI can suggest modifications to content based on prior sales, marketplace analytics, or channel data. These adjustments could include changing the wording, promoting certain features, or changing the order of attribute importance.
Instead of treating every SKU the same, these predictive insights enable product teams to make smart decisions about how to use their resources.
Predictive analytics turns static product catalogs into datasets that can change and respond. AI can suggest which features promote sales on certain platforms or markets by looking for patterns in how people connect with and convert. For example, it may show that “energy efficiency rating” has a bigger effect on sales in European channels than “installation time” does in North America.
In the same way, predictive pricing models provide businesses the option to change prices on the fly based on changes in demand or competitors. When used with PIM data, these models connect product content optimization with business strategy, which leads to better channel performance and a verifiable return on investment.
4.5 Workflow Automation with AI: From Trigger-Based Enrichment to SLA Compliance
AI integrates deeply into process workflows. Within a modern PIM, automation may include:
Trigger-driven tasks: For instance, AI can automatically update attributes, write copy, and send exceptions to be reviewed by a person when a new SKU is added.
Service-level automation (SLA): AI technologies make sure that turnaround times are met by automatically escalating incomplete records, letting stakeholders know, or giving work to other people if limits are broken.
Human review only in cases of exception: Only goods with low confidence scores or data that don’t match up are reported for human assessment. This cuts down on the amount of labor that needs to be done.
Continuous revalidation: After publishing, periodic scans look for drift, abnormalities, or mismatches and start corrective operations.
The result is that products are ready faster, there are fewer bottlenecks, and product data pipelines are always managed.
AI-driven workflow automation, when used with event-based triggers, makes sure that PIM systems are not just storage spaces but also active, responsive engines. For instance, when a new product record is added to the system, AI may immediately find missing attributes, add to descriptions, check image metadata against other sources, and send low-confidence data for review—all before the product goes online.
This also helps meet compliance SLAs by keeping comprehensive audit trails, version histories, and validations with timestamps. In big companies, these workflows make it possible to have scalable governance, which means that no product may go into distribution channels without meeting certain quality and accuracy standards.
AI will help PIM teams move from reactive data management to proactive data governance in the long run. This will speed up the process and keep data integrity at an enterprise level across brands and regions.
4.6 Implementation Best Practices: Public vs. Private Models and Security Considerations
Implementing AI in corporate PIM systems necessitates meticulous architectural and security planning:
Public vs private models:
Public models, like GPT and open-source LLMs, can be set up quickly and have a lot of power, but they may also raise issues about data leakage.
Private or fine-tuned models (hosted in your environment or on dedicated infrastructure) give you greater control and privacy, but they take more time to set up and keep up.
A hybrid approach is often ideal: use public models for non-sensitive tasks, and route proprietary or compliance-sensitive data through private models.
Data governance and auditing: Every modification made by AI should have a version number, be linked to a person, and be able to be checked. For outputs with low confidence, human monitoring must be possible.
Bias and quality of training data: To avoid bias, make sure that models have high-quality, representative product data. This will also make sure that the models are accurate in their domain and don’t hallucinate.
Model renewal and monitoring: AI models get worse over time; therefore, they need to be retrained on new product data and have feedback loops all the time.
Integration and APIs: The AI modules need to work well with the PIM’s API ecosystem so that there are no silos or problems with operations.
Companies can use strong automation without putting data security or compliance at risk by using these deployment precautions together with mature AI models.
Security and privacy are still the most important things for businesses to implement. Zero-trust data frameworks must be followed by modern PIM architectures. This means that no sensitive product data, like supplier pricing, proprietary materials, or safety formulations, can leave the company without encryption or control. For industries that are regulated, keeping local AI endpoints for data processing makes sure that they follow the rules set by GDPR, ISO 27001, or SOC 2.
Finally, setting up human-in-the-loop oversight protects against excessive automation. Changes made by AI should be able to be traced, undone, and checkable. Businesses can get AI-driven scalability without giving up compliance, trust, or control by using a combination of transparency, ethical model training, and domain-level tailoring.
4.7 Choosing the Right LLM for B2B: Capabilities, Privacy, and Compliance
As AI becomes central to B2B operations, understanding the landscape of Large Language Models (LLMs) and their ideal use cases is critical. The right model depends on the nature of your workloads, your data sensitivity, and your regulatory environment. Below is a practical overview of today’s leading LLMs and how they map to common enterprise scenarios.
Model
Best For
Notable Strengths
OpenAI – GPT-4.1 Family (main/mini/nano)
Generalist agents, coding, and long-context workflows
Excellent reasoning, tool use, and massive context window (~1M tokens); ideal for catalog or contract processing.
Public LLMs: Ensure vendor provides a signed DPA, transparent subprocessor list, no-training guarantees, and regional processing (EU-only endpoints where possible).
Private LLMs: Control inference and logs within your perimeter, using your own KMS and encryption policies. This enables full compliance with Articles 28–32 of GDPR and reduces DPIA risk.
Hybrid Approach: Many enterprises route prompts dynamically—sending sensitive queries to private models while using public APIs for low-risk, high-IQ tasks like taxonomy generation or copywriting.
What This Means for PIM Deployments
For B2B environments, the optimal setup is typically hybrid:
Use private or open-weights LLMs (Llama, Mistral) for sensitive or regulated data such as supplier contracts, pricing sheets, and technical drawings.
Use public LLMs (GPT-4.1, Claude, Gemini) for low-risk, content-generation workflows such as product copy, taxonomy mapping, and SEO metadata.
Implement a model gateway within your PIM that handles prompt routing, PII redaction, and audit logging.
Conduct a DPIA and document all retention and data-transfer policies to stay compliant with GDPR and enterprise security mandates.
By balancing capability, governance, and cost, enterprises can confidently adopt AI that enhances productivity while preserving brand trust and regulatory compliance.
5. AI Across the B2B Product Lifecycle
Artificial intelligence (AI) can handle every step of managing product information, from making the first content to distributing it, making sure it is compliant, and unlocking old data assets. When used wisely, AI becomes the engine that drives value, consistency, and scale over the entire lifetime. Below, we look at four important areas where AI makes a difference in B2B PIM.
5.1 Hyper-Personalization for Product Content
In B2B situations, it’s often necessary to create content that speaks to a variety of people, such as engineers, procurement teams, regional distributors, or niche industry verticals. AI lets you hyper-personalize by making many different versions of content from a single core product record. AI can change the tone, focus, technical depth, or local units of information on the fly, so you don’t have to write distinct descriptions, spec sheets, or sizing documents for each audience or market.
This “one-to-many” way of making material cuts down on the amount of manual work needed to customize it while keeping things consistent. Because content is more relevant to the reader’s situation, conversion rates go up. Average order values (AOV) may go up because product messaging is more aligned, and sales cycles can be shorter because content clearance waits are shorter.
AI-driven customization makes sure that every product listing is more than simply a translation or a change in size; it also makes sure that it fits the buyer’s needs. For example, a global HVAC company might use AI to automatically change technical information for different types of people. An engineer might get CAD-compatible spec data, a procurement manager might get information about warranties and the cost of ownership, and a reseller portal version might focus on how easy it is to install. By using a single source of truth in the PIM, these audience-specific versions stay in sync. This keeps brand, compliance, and technical accuracy without having to modify them over and over again.
This kind of scalable customization is good for business in a direct way. Companies that have tried it out in test programs for industrial manufacturing and building materials say that quote-to-order processes are up to 25–35% faster and that buyer engagement metrics on digital channels are up. The long-term result is not only better marketing, but also a stronger link between data accuracy and buyer trust.
5.2 Data Syndication and Channel Distribution
Once the content of a product is improved and made more personal, it needs to be sent to all of the right downstream channels, such as B2B portals, eCommerce platforms, marketplaces, partner catalogs, and regional websites. AI helps with this by automatically changing formats, mapping taxonomies, and changing channels. For instance, AI models can change the format of descriptions to fit character constraints, change units, map attributes to each channel’s taxonomy, and have the data ready for revisions in real time.
Companies may grow their channel footprint without hiring more people by using AI-driven syndication. When product data feeds flow more smoothly and reliably, launching in new channels becomes easier, listing errors go down, and time-to-market is shortened.
In a traditional paradigm, taxonomies, attribute fields, and compliance standards must be manually aligned for each new channel or marketplace integration. AI gets rid of this problem of linear scaling by learning from prior mappings and utilizing the same logic at different places. It changes data automatically to fit the format of each channel, such as Shopify’s JSON schema, Amazon’s flat file templates, or GS1 standards for B2B trading.
AI-driven syndication may also keep an eye on live data differences and change listings on the fly. AI models may spot errors, apply adjustments, and make sure that data is synchronized across all endpoints when a marketplace changes its attribute name or adds new requirements, such as sustainability certificates.
This automatic distribution layer not only cuts down on manual work, but it also makes sure that product data, prices, and images are always the same, no matter where the buyer sees them. Companies that use AI for syndication on a wide scale have said that it speeds up time to market by up to 60% and cuts down on channel listing mistakes that used to hurt customer trust.
5.3 Safety Data Sheet (SDS) Processing
Safety documents, like SDS files, are needed for many B2B industries, including chemicals, industry, medicine, and electronics. Compliance teams usually verify PDFs, re-enter material, make sure translations are correct, and check references by hand. AI changes that: models take in SDS documents (including scanned or embedded PDFs), pull out structured data, make draft sections, translate text, and format outputs for different markets.
This not only speeds up the process of getting new items approved by regulators, but it also cuts down on mistakes and the need for oversight. AI makes it easier to market regulated products in many parts of the world since it can naturally handle outputs in multiple languages. The end consequence is quicker access to the market and more faith in compliance.
AI’s effects on SDS management go beyond just making things easier; it also makes them more consistent and easier to track. AI makes sure that every attribute is properly indexed and versioned inside the PIM by pulling out structured data like hazard codes, chemical compositions, or safety handling instructions. This lets compliance teams check updates against each other, use localized templates (such as EU REACH or OSHA forms), and keep all of their regulatory data in one place.
Additionally, the ability to generate documents in many languages means that SDS versions may be automatically created for different countries. This speeds your entry into international markets without the risk of translation problems. Companies that use AI to process documents have gotten regulatory preparedness up to 70% faster than those who do it by hand in industries where product launch schedules are often related to SDS approval.
The fundamental benefit is not just compliance efficiency, but also company agility. This means that businesses can bring new formulas or materials to market knowing that their paperwork will always be up to date, correct, and ready for an audit.
5.4 Unlocking Legacy Data
Old catalogs, PDF datasheets, technical drawings, and historical supplier paperwork are some of the best places to find product information. You can’t really use these assets in their basic state. AI models, especially when OCR is used with structural understanding, can get data from these unstructured sources and turn it into organized attribute tables.
By doing this, businesses may avoid costly and error-prone manual rekeying, make money from long-tail SKUs, and make sure that data is consistent between old and new records. Once old data is unlocked, it can be compared, searched, and integrated, which fills in gaps in the catalog and makes analytics, filtering, and content completeness better.
In many businesses, 60–80% of product data is stuck in old documents like scanned spec sheets, vendor PDFs, and old ERP exports. AI-driven extraction gets rid of this “dark data” layer and turns it into useful information. Models that have been trained in OCR and structural parsing can understand layout, hierarchy, and embedded visuals like technical drawings or tables. They can then turn these into normalized attribute forms that can be used in the PIM.
Once this information is organized, it can be used for a lot of business opportunities. Long-tail SKUs that were not able to be added to digital catalogs before because they didn’t have all the information they needed can now be published online, make money from, and be improved for search visibility. Also, unified attribute models make it easier to run analytics, like tracking performance or sustainability, on both old and new datasets.
In the end, unlocking legacy data turns a static archive into a living digital asset, allowing businesses to use decades of product knowledge for modern business. This ongoing modernization loop not only makes the catalog more complete, but it also helps people make better decisions throughout the product lifecycle.
6. The Hard ROIs of AI in PIM: Quantifying Financial Impact
The most crucial thing for every business that is looking into AI-in-PIM is to turn AI capabilities into real money. This part demonstrates to procurement and finance teams how to utilize real-world formulas to figure out how much money they can save and how much money they can generate. It also discusses the main reasons for each calculation and gives examples to make the arithmetic easier to understand. The goal is simple: show how to turn automation, faster listings, and better product data into money and payback times that executives can understand.
We need to look at AI’s business impact not just as a way to make things run better, but also as a financial result that can be modeled, tracked, and reported. Businesses may turn what used to be “innovation” into measurable return on investment by breaking down AI’s effects into concrete measurements like saved labor hours, fewer errors, faster product launches, or new channels opened. This analytical approach makes sure that every PIM improvement supports financial and strategic goals and is in line with what CFOs want from AI.
Savings from replacing or adding to manual copywriting with LLM-assisted generation and a little bit of human evaluation.
Formula (labor savings): Annual Copywriting Cost Savings = D_p × T_human × C_hour
Where: D_p = number of descriptions produced or updated with AI per year
T_human = average hours previously spent by a human per description.
C_hour = fully loaded hourly cost for the writer/editor (salary + overhead)
Find out how many pages or SKUs you make or change each year and how long it takes a writer to do it now. To get a realistic approximation of your savings, multiply by the fully loaded rate. Add a second line for quality/acceleration impact: earlier listings can bring in more days of revenue (see the section on acceleration below).
Worked example. If you produce or update 20,000 descriptions per year (D_p = 20,000), each took 1.5 hours to draft before AI (T_human = 1.5), and a fully loaded hourly cost is $40 (C_hour = 40), the annual labor savings are:
20,000 × 1.5 × 40 = $1,200,000.
Copy AI not only cuts down on labor costs, but it also speeds up ROI by making money from launching items days or weeks early. That speed advantage grows in situations where every day of delay implies fewer sales. For instance, a manufacturer that adds seasonal or promotional SKUs can get online sales to start up faster across all channels, which will enhance the annual sell-through rate. The result is both saving money and getting money early, which shows that product copy made by AI can make money.
6.2 Image-Based Product Attribution ROI
Using vision models to tag photos (color, material, component, alt text) saves time and makes onboarding faster.
Formula (labor savings): Annual Image Tagging Savings = I × (T_tag / 60) × C_hour
Where: I = images processed per year.
T_tag = average manual tagging time in minutes per image
C_hour = hourly labor cost
Count how many photographs are added or normalized each year and guess how long it takes to do each one by hand. If you now hire someone else to tag images, compare the expenses of doing it in-house after AI.
Worked example. For 50,000 images per year, 4 minutes per image manually, and $25 hourly labor cost:
50,000 × (4 / 60) × 25 = $83,333 (approx).
Automated picture tagging has a multiplier impact when used on thousands of SKUs. In addition to saving money on direct labor, businesses get more consistent metadata, fewer catalog mistakes, and speedier SKU onboarding. AI picture tagging has a direct impact on customer discovery and conversion in businesses where images are important, such as clothing, furniture, and consumer products. Tagging colors, materials, and styles correctly makes it easier to find things, get better recommendations, and see things more clearly on digital shelves. So, Image AI becomes a quiet force for both efficiency and discoverability.
6.3 Color AI for Variant Standardization
Efficiency is obtained by labeling different color attributes, which also leads to fewer returns because of color mismatch.
Where: V_c = number of variant entries processed per year
T_color = hours per variant for color work
Return_rate_before/after = return rates before and after color standardization
N_orders = number of orders affected per year
C_return = average cost per return (logistics + restocking + refunds)
Worked example. If you handle 100,000 variation submissions and each one takes about 0.02 hours (72 seconds) to do by hand at $25/hour, you save $50,000 in labor costs. If the return rate goes down from 6% to 4.5% on 200,000 orders where color is important and it costs $30 to handle each return, the savings would be (0.06 − 0.045) × 200,000 × 30 = $90,000.
Color AI affects how customers feel about a brand and how they see it. When colors are shown correctly, it makes it easier for customers to understand what they are getting, which cuts down on returns and the costs that come with them. Standardized color data feeds also help make sure that eCommerce images, printed catalogs, and packaging all look the same across all marketing channels. These changes make the brand more reliable and the operations more predictable over time. This is very important for global multi-channel retail.
6.4 Bulk Attribute ETL Automation with Pimbles
The “do once, reuse everywhere” effect shows how useful it is to link micro-automations together to extract, transform, and load properties on a large scale.
Where: A_t = number of attribute entries auto-filled per year
T_manual = hours per attribute manually
N_tasks = number of discrete tasks automated per year (e.g., product spec pulls, batch translations)
H_task = manual hours per task
Get both micro (attribute) and macro (task) impacts. Attribute automation builds up over time across SKUs and channels, while task automation gets rid of operations that need to be done by hand over and over again. Count the number of qualities or activities and the amount of time it would take to do them by hand. This is frequently a safe but convincing way to do things.
Worked example. If a program fills in 1,000,000 attributes a year and takes 0.01 hours and $30 an hour to do so, the savings are 1,000,000 × 0.01 × 30 = $300,000. If you get rid of 50,000 manual jobs that each took 0.5 hours, you save 25,000 hours. At $30 an hour, that’s $750,000.
In addition to doing math, this technology lets firms grow their catalogs without having to hire more people. Pimbles lets teams copy workflows that have already been set up in different departments, suppliers, or marketplaces. Because this micro-automation is consistent and can be repeated, subsequent updates, reformatting, or audits will need very little help. Over time, the value grows because of both savings and a quicker response to changes in the market.
6.5 Automating Data Sheet Processing (SDS, technical sheets)
OCR and structured extraction help avoid specialist labor and get things ready for compliance faster.
Where: docs_per_year = number of SDS/spec/docs processed annually
hours_manual_per_doc = hours previously required for a technical specialist to extract/format/compliance-check
labor_cost_per_hour = fully loaded specialist hourly rate
Worked example. 5,000 regulated documents processed each year at 2 hours each and $50/hour specialist cost: 5,000 × 2 × 50 = $500,000.
It is harder to put numbers on things like subtracting fines, avoiding delays in the launch of regulated products, and lowering legal risk, but they should be incorporated qualitatively and, where possible, turned into predicted avoided cost lines.
AI in document processing has a compounding return on investment (ROI) when used in fields like manufacturing, life sciences, or chemicals. Automating SDS parsing and compliance checks cuts down on the time it takes to complete a cycle, lowers the need for specialized review, and speeds up the process for new SKUs. AI also lowers the chance of human error, which helps businesses keep a good compliance record and protects them from regulatory or reputational risk.
6.6 AI-Enabled Channel Growth and Marketplace Expansion
Adding SKUs to new channels fast can lead to more profit because AI handles channel changes, mapping, and localization.
Formula (annual incremental profit from new channels). ΔProfit = N × M × V × P × (GM% − MC%)
Where: N = number of products listed per new channel
M = number of new channels added in the period
V = units sold per product per year on the new channel
P = average price per unit
GM% = gross margin percent on product (decimal)
MC% = marketplace or channel commission percent (decimal)
Worked example. Putting 5,000 items on three new channels, where each one sells 10 pieces a year for $120 with a 40% gross margin and a 10% marketplace fee:
ΔProfit = 5,000 × 3 × 10 × 120 × (0.40 − 0.10) = $5,400,000 incremental annual profit.
This shows how AI’s ability to make a lot of channel-ready content quickly leads to new, high-leverage sources of income.
For enterprises managing thousands of SKUs across multiple eCommerce ecosystems, AI syndication provides a non-linear scalability advantage. AI automates changes and taxonomy alignment instead of adding more people to each team. This lets markets grow at a far lower cost than usual. Over the course of a fiscal year, these little profit streams can turn AI-in-PIM from a tool for running a business into a way to make money directly.
6.7 Revenue Enablement Narrative: Catalog Expansion and Speed
ROI isn’t just about saving money. AI makes money in two ways: by adding more sellable SKUs (catalog expansion) and by speeding up the time it takes to get products to market (speed to market). How to turn AI results into money:
Catalog elasticity: Figure out how many more SKUs AI can sell (ΔSKUs). To achieve more gross profit, multiply ΔSKUs by the average number of units sold per SKU and the contribution margin.
Acceleration capture: For new product releases, find the daily contribution margin and multiply it by the number of days that AI can get a product live sooner. Add up the affected SKUs to get an idea of how much money faster time-to-market will bring in.
Both of these factors contribute to the direct labor savings formulae above and often have a bigger impact on long-term value.
7. Pimbles: AI-Powered Product Workflow Automation (Powered by Pimberly AI)
Pimbles represent a big step forward in how firms can use AI to manage their product information. Pimbles are flexible, user-configurable AI prompts that make it easier than ever for Pimberly users to get, change, and create product data. They fill the gap between handling manual data and automating it in a way that can grow with the business. This helps companies add more information, improve compliance, and provide better product experiences across all channels.
Users can employ automation with Pimbles without having to write code or rely on outside development. Each Pimble is a reusable, testable building block that can tackle difficult data tasks, including getting information out of unstructured files or writing product descriptions that are good for SEO, all in a safe and controlled environment.
7.1 Understanding Pimbles: The Foundation of Intelligent Automation
A Pimble is basically a customizable AI prompt that is incorporated right into Pimberly. With these prompts, users may do smart things with product data, such as pulling information from documents and photographs, making new content from existing attributes, or changing data into the right format for different systems and audiences.
Pimbles can:
Extract information from images and documents to populate attributes.
Use existing attributes to generate copy, content, or images.
Translate, repurpose, or reformat any attribute or text block.
It can be applied to multiple products in bulk or chained together into a sequence for multi-step processing.
Businesses can customize automation to meet their own compliance, domain expertise, and creative needs by choosing the large-language model (LLM) that works best for them. This could be ChatGPT, Claude, Gemini, LLaMA, DALL·E, or even a unique in-house model. After being set up, a Pimble may be used on thousands of SKUs with just a few clicks, which will greatly increase the productivity of data teams, marketers, and eCommerce administrators.
Pimberly envisions Pimbles as a toolkit that will change over time as customers try new things and come up with new ideas. The options are endless. Every Pimble helps businesses get closer to intelligent automation by making conforming picture alt text, extracting standardized specs, translating multilingual product data, or checking regulatory comments.
In order to make this useful, Pimbles organizes its features around five main workflows: Generate, Extract, Enrich, Standardize, and Validate. Each one is designed to solve a real business problem in managing product data.
Generate – Create new content such as product titles, descriptions, SEO metadata, campaign copy, or accessibility text.
Extract – Pull structured data from unstructured files, PDFs, labels, or imagery.
Enrich – Add depth, context, or clarity to existing information, such as FAQs, pairing tips, or warranty summaries.
Standardize – Normalize attributes and formats for syndication or marketplace feeds.
Validate – Check accuracy, completeness, and compliance of product information.
These categories show how Pimbles turn static product data into a live, smart asset that helps with every step of the product-information lifecycle.
7.2 Building and Managing Pimbles: How Customers Create and Apply Them
Pimberly has a structured but easy-to-use way for both business and technical users to create and manage Pimbles. The goal is to make it easy to build up, test, and reuse smart automation across large amounts of product data without needing to know how to code.
Users can go to Pimbles by going to Admin > AI > Pimbles. There, they can make, test, and save configurations in a central library. You can use the “Pimberly AI” button in the Products view to apply a Pimberly to one or more products on its own or as part of a sequence.
This process ensures control, transparency, and repeatability, allowing organizations to establish standardized AI-driven workflows that enhance data accuracy and reduce manual intervention.
Creating a New Pimble
Every Pimble starts as a customizable AI prompt. Users first give it a descriptive name and a short synopsis when they make one. This makes it easy to find later.
Users then choose the AI model that is best for the job. You can choose from big language and multimodal models as GPT-4o, Claude 3.5 Sonnet, Gemini 2.5 Flash, LLaMa 3.2, and DALL-E 3. Each model has its own strengths: Claude is good at summarizing long texts, GPT-4o is good at working with complicated structured data and images, Gemini is good at working with both text and images, LLaMa is good at text-only tasks, and DALL-E is good at making visual outputs.
After choosing a model, users pick the target attribute (such as Product Description, Technical Specification, or Alt Text) to tell the program where to write the output. Then, they can add media sets, such as photographs or PDFs, that the model should use as a reference while it works.
After that, the user types the prompt and uses the “Add Attribute” tool to add variable product fields on the fly. This lets the Pimble pull contextual product info (such as brand, material, and size) right into the AI request.
Once the setting is done, users try out the Pimble on a test product. They can see and regenerate outputs, changing the prompt and variables until the result is what they desire. Once you’re happy with it, the Pimble is saved and turned on.
Version Management and Governance
Every Pimble keeps a record of all versions, which makes sure that there is a full audit trail of the prompt wording, the models chosen, and the output mappings. Before a version can be made active, it must have valid text, a defined model, and an output attribute that has been assigned.
The active version history keeps account of all changes, including when a version was changed, which model was utilized, and what text was live at the time. These entries can’t be changed, which keeps full traceability for quality assurance and compliance.
This built-in governance makes Pimbles suited for business. It lets businesses show that they have control over how AI-generated outputs are made, checked, and used, which is very important for industries that are regulated or deal with sensitive data.
Best Practices for Creating Effective Pimbles
To achieve optimal results, Pimberly recommends a few operational best practices:
Split complex operations into several Pimbles and link them together in order. For instance, you could use one Pimble to get important information from a product image and another to write marketing copy utilizing that information.
Be precise and systematic in your prompts; make sure to spell out the length, tone, and format of the output. For example, “Return the country of origin from the spec sheet, like Germany.”
Use backup instructions to deal with missing data, like “If the value can’t be found, write ‘N/A’.”
Add tone and audience signals to the marketing content generation process, like “Tone: professional and to the point.” People who buy home appliances.
Select the right model for each task:
Claude 3.5 Sonnet – long-form summarization and precise reasoning over documents.
GPT-4o – structured data extraction and image-to-text analysis.
Gemini 2.5 Flash – handling both images and long text inputs simultaneously.
LLaMa 3.2 – text-only data conversion or field normalization.
DALL-E 3 – generating images or visual content from product descriptions.
These guidelines help ensure accuracy, consistency, and compliance across all automated workflows.
Applying Pimbles to Products
You can use Pimbles in bulk or one at a time after saving them. Users can choose or filter several products and then click the “Pimberly AI” button to launch the Pimble selection window. After that, they decide which Pimbles to use and in what order. Pimbles can run one after the other, with one output feeding into the next, or they can work on various qualities at the same time. Users click Generate to process the results after they have been checked.
The data that comes out goes straight into the given product properties. You may check outputs quickly in the product detail view before giving your permission or publishing them. This seamless integration makes sure that AI automation stays in line with current data governance standards, which gives consumers trust in both performance and accuracy.
7.3 Pricing and Deployment Model: Scalable and Transparent
Pimbles work inside the current AI pricing and deployment framework of Pimberly. Each Pimble execution uses up a token, whether it’s in testing or production. This token-based methodology makes things clear and lets businesses control costs in a predictable way, so they can reliably analyze ROI and plan how to use AI.
Pimbles are embedded into the basic Pimberly AI infrastructure, so you don’t have to install or maintain them separately. All executions take place in the same secure, compliant framework that controls other AI activities in Pimberly. This guarantees enterprise-level reliability from the start.
7.4 Real-World Use Cases: Turning AI into Everyday Efficiency
Pimbles are made to handle the complicated product data that businesses have to deal with. Some such uses are:
Accessibility and SEO: Using image-to-text scanning to produce alt text that meets WCAG standards and metadata that is optimized for keywords.
Writing step-by-step cleaning or assembly instructions from safety-sheet PDFs or getting PPE advice from SDS files is an example of compliance and documentation.
Specification Standardization—getting product specs from unstructured data sources and making them all the same.
Finding allergies and ingredients—using spreadsheets or labels to find allergens or restricted components to make sure the information is correct according to the law.
Product Enrichment: Making care directions, lifestyle descriptions, or advertising text that is specific to each channel or persona.
As more people use Pimbles, companies are finding new methods to use them, such as automating translations, increasing taxonomy labeling, checking the integrity of data, and creating unified content pipelines that make things easier and more accurate.
7.5 The Road Ahead: Expanding the Power of Pimbles
As part of Pimberly’s early adopter program, Pimbles are being added. This gives users the chance to help influence how this feature grows. Pimberly will add new features to the Pimbles ecosystem over the next few months to improve visibility, governance, and control. These features will include:
Pimbles in Workflows: The ability to start Pimbles directly in Pimberly workflows, which means that actions can be automated based on events, conditions, or lifecycle stages.
Logging Integration: Connecting Pimble submissions to Pimberly’s logging system to make it easier to keep track of jobs, deal with errors, and fix problems.
Token Management Tools: New administrative controls for managing Pimble tokens that let you see how they are being used, make sure they are distributed fairly, and support automated resets every year.
These new features will enable clients to automate more of their product data procedures, which will make them even more efficient and scalable.
7.6 Alignment with Sales Enablement and Customer Communication
When talking to potential consumers and clients about Pimberly AI and Pimbles, it’s important to be consistent and accurate. Pimberly has made special sales enablement tools to make sure that messaging matches up with verified functionality.
These materials include:
Sales sheets and product overviews.
Presentation slides and proposal templates.
Schematics, screenshots, and customer-ready examples.
Elevator pitches, value propositions, and objection-handling guides.
Sales and marketing teams can talk about the benefits of Pimbles with confidence by using these official sources. This is because they are based on real use cases and value pillars instead of made-up examples.
7.7 Strategic Impact: Enabling Scalable, Measurable Product Data Transformation
The launch of Pimbles marks a big change in how businesses use AI. Businesses can now use controlled, repeatable, and scalable AI processes directly in their PIM instead of depending on one-time or experimental automations.
This implies that producers, distributors, and retailers can get products on the market faster, have more accurate catalogs, and have uniform global branding, all achieved through transparent, auditable automation. Pimbles let you govern things while cutting down on manual work, which leads to measurable improvements in data quality, compliance, and time-to-market.
In the end, Pimbles turns AI from a minor feature into a key part of operations, driving ongoing improvement, real ROI, and a long-term competitive edge in the current digital economy.
8. Visuals, Tools & ROI Insights
To understand how AI can help with product information management, you need a clear way to look at and talk about ROI. This part turns quantitative models and operational results into useful business information that helps decision-makers clearly see how much money they can save, how much more efficient they can be, and how easily they can grow. The following descriptions show how companies can figure out, compare, and talk about the business impact of intelligent automation in PIM.
8.1 ROI Formula Summary and Financial Calculator
Every investment in automation must have a return on investment (ROI) that can be measured and verified. Each workflow adds a specific financial return through things like automating product copy, tagging images, standardizing attributes, Pimbles ETL, compliance documentation, and expanding channels.
A full ROI reference table can sum up these calculations by listing the most important factors, such as:
Number of SKUs processed per year (Dₚ, I, V꜀)
Average manual time per unit (Tₕuman, Tmanual)
Fully loaded hourly cost (Cₕour)
Return rate and average return cost (Creturn)
Conversion uplift, units sold, and gross margin (V, P, GM%)
These factors are what you need to figure out how much money you can save on labor, how much less you can spend on mistakes, how much more money you can make from new channels, and how long it will take to pay back the investment. Organizations can use these inputs in a basic Excel or web-based calculator to model several adoption scenarios, such as conservative, moderate, and aggressive, to get a better idea of what will happen. Being open about the assumptions that go into these estimates is important for gaining the trust of stakeholders.
8.2 Manual vs. AI Workflow: A Comparative View
Switching from manual data handling to AI-augmented procedures alters how well operations run. In traditional product data workflows, from onboarding to enrichment and syndication, each activity usually goes via several human touchpoints. This can cause delays, discrepancies, and problems with getting clearance.
AI-driven workflows, on the other hand, use smart automation to replace tasks that need to be done again and over again. For example, Pimbles lets you quickly extract, translate, or validate content across thousands of SKUs. There are still checkpoints where people need to make decisions or check for compliance, but most of the work that needs to be done over and over again is gone.
Organizations typically observe measurable efficiency gains, such as:
A 50–70% reduction in handoffs across content and data teams
A significant increase in products processed per FTE
Cycle-time compression from days or weeks to hours
8.3 AI Across the Product Data Lifecycle
AI is now a part of every step of the product data lifecycle. There are chances to provide demonstrable value at every stage, from the first development of content to compliance and modernization.
Create & Ingest: AI helps turn supplier data and unstructured assets into product records quickly.
Enrich & Validate: Pimbles automates the creation of copies, the standardization of attributes, and the addition of metadata.
Asset Management: Vision models automatically tag and sort images so that they may be searched and are in line with rules.
Syndicate & Localize: Multilingual LLMs make descriptions and SEO-ready metadata for each channel.
Compliance & SDS: AI pulls safety information straight from PDFs or other regulatory papers and checks it for accuracy.
Legacy Modernization: OCR and generative models turn old product data into digital files that can be used in other systems.
These steps show how AI drives modernization from start to finish, not as separate jobs but as a one cycle of smart automation.
8.4 Pimbles in Action: From Input to Insight
Pimbles are the driving force behind Pimberly AI’s workflow automation. They turn different types of data inputs into outputs that are structured, compliant, and ready for publication.
A standard Pimble process starts with things like PDFs from suppliers, pictures of products, or raw text attributes. The Pimble uses a model that is best for the job to apply pre-defined logic, such as OCR extraction, content generation, or attribute validation. For example, GPT-4o is best for structured extraction, Claude is best for summarization, and DALL-E is best for visual metadata.
Each run has configurable confidence thresholds, which let you mark outcomes that aren’t sure enough to be approved by a person. The final results are automatically put into PIM fields, and there are comprehensive audit trails for them. This end-to-end procedure makes sure that every automated output is clear, controlled, and ready for business.
8.5 Quantifying Efficiency Gains
Key performance indicators (KPIs) show the measurable effects of using AI in a way that has a real effect on the business:
Products processed per FTE: A direct sign that throughput has been better.
Annual hours saved by function: Shows how much time may be saved on duties like copywriting, tagging, and compliance.
Cumulative cost avoidance and payback period: Keeps track of when the AI investment breaks even.
Revenue uplift from faster channel launches: Links faster time-to-market to higher sales over time.
These numbers make the case for intelligent automation even stronger. For example, a catalog with 200,000 SKUs that uses copy automation and Pimbles-enabled ETL might cut down on manual labor by several full-time employees, speed up product launches by weeks, and pay for itself in less than a year. The outcomes depend on how complicated and widely used the system is, but the ROI is always clear.
9. Conclusion: The Future of PIM Is Intelligent
AI in Product Information Management is a set of useful tools that businesses can use right away. It is already transforming the way B2B companies develop, manage, and sell product information. We have proven in this study that when used appropriately, AI takes the boring parts out of product-data work, lowers risk, and makes it easier to find new sources of income. Most businesses are no longer asking themselves if they should adopt, but how to do so in a responsible way and measure the effects.
9.1 AI in PIM is a “Now” Technology, Not a Future Promise
Language models, picture recognition systems, and domain-specific extraction tools are all mature enough to produce consistent results in real-world settings. Live deployments have shown that automatic description creation, image tagging, PDF specification extraction, and channel-specific copy modification are all useful. These features take away most of the manual work from everyday chores, allowing subject-matter specialists to focus on more important tasks, including enhancing product strategy, adding more content, and supporting channels that bring in more money.
9.2 Delivering ROI Through Cost Savings and Revenue Growth
It’s easy to see how AI might help PIM financially. On the cost side, automation cuts down on the time spent on copywriting, tagging, color standardization, and compliance documentation. These are measurable reductions in labor that increase with the number of SKUs. Faster time-to-market, consistently full listings, and personalized product experiences all help people find your products, buy them, and spend more money on them. When you add together lower operating costs, a bigger selection of items that may be sold, and faster launches, companies can see a clear, measurable return on their investment. When AI is used in the correct processes, it is possible to see tenfold increases in throughput or significant decreases in time-to-market in many real-world situations.
9.3 Secure, Compliant, and Enterprise-Ready AI Deployments
Risk and governance are two very important parts of any AI initiative for a business. When PIM is set up correctly, it keeps low-sensitivity jobs (where public models are fine) away from high-sensitivity or regulated data that needs private models or on-prem/private endpoints. Role-based permissions, human-in-the-loop review gates, audit logging, and confidence thresholds all help keep track of things and lower the chance of not following the rules. These safeguards let legal, compliance, and IT departments use AI while keeping a close eye on what data goes to outside models and where human consent is still needed.
9.4 Lifecycle-Wide Benefits: Personalization, Compliance, and Modernization
The value of AI isn’t just in one task; it builds up across the life of the product. AI is involved in every step, from quickly making products and writing highly personalized descriptions to automatically syndicating them across channels, extracting SDS for regulatory releases, and updating old technical data. The result is a better experience for customers, better readiness for regulations, fewer returns, and a quicker way to enter new markets. This boost over the entire lifecycle is when businesses go from making little changes to gaining a strategic advantage: more detailed, reliable product data becomes a selling point instead of a cost center.
9.5 Pimbles as the Path to Continuous, Scalable AI Adoption
To make AI work, you need to build elements that can be used over and over again and are controlled. Pimbles are configurable AI micro-services that do ETL-style functions on product data. They give that structure. They let you establish inputs, choose models or actions, set confidence thresholds, and send exceptions to people. Pimbles can be used on demand, in planned batches, or as part of a product’s lifetime. They make it possible to grow, audit, and improve all the time. For businesses, Pimbles are the practical link between pilot initiatives and enterprise-level automation. They have governance in place, measurable results, and quick iterations.
4.7 Choosing the Right LLM for B2B: Capabilities, Privacy, and Compliance
As AI becomes central to B2B operations, understanding the landscape of Large Language Models (LLMs) and their ideal use cases is critical. The right model depends on the nature of your workloads, your data sensitivity, and your regulatory environment. Below is a practical overview of today’s leading LLMs and how they map to common enterprise scenarios.
The Short List: Most Common LLMs and Their Strengths
| Model | Best For | Notable Strengths |
|——-|———–|——————|
| **OpenAI – GPT-4.1 Family (main/mini/nano)** | Generalist agents, coding, and long-context workflows | Excellent reasoning, tool use, and massive context window (~1M tokens); ideal for catalog or contract processing. |
| **Anthropic – Claude (3.5 Sonnet / 4.5)** | Enterprise analysis, policy/compliance reviews, structured writing | Strong guardrails, contextual accuracy, and large 200K-token context—well-suited for regulated data. |
| **Google – Gemini 1.5 / 2.0** | Ultra-long context and multimodal tasks | Handles docs, images, audio, and video; perfect for “drop-the-binder-in” use cases like spec sheets and tech packs. |
| **Meta – Llama 3.1 (405B, open weights)** | On-prem or self-hosted deployments | Fully customizable, low-latency, EU-residency-friendly for organizations needing full data control. |
| **Mistral – Large 2 / 2.1 / Medium 3** | Workflow automation and function calling | Strong for cost-efficient, EU-hosted agentic processes; ideal for data enrichment and RAG use. |
| **Cohere – Command (R / R+ / A)** | Enterprise RAG and private search | Tightest privacy posture; excels at querying over private data stores like PIM/ERP. |
| **xAI – Grok** | Real-time data monitoring and search | Best for live web or ops intelligence; newer enterprise support ecosystem. |
When to Use Each Model
– Product enrichment and spec-sheet automation: GPT-4.1 or Claude for accuracy and structured reasoning; Gemini for massive or multimodal files.
– RAG over product or ERP data: Cohere Command or Mistral Large for secure retrieval and quick results.
– Compliance or policy reviews: Claude for interpretability and safe summarization.
– Integration and agentic workflows: GPT-4.1 or Mistral for function calling and tool use.
– Self-hosted or regulated industries: Llama or Mistral for full residency control.
– Live monitoring of market/ops data: Grok for real-time retrieval.
Public vs. Private LLMs
| Aspect | **Public (Multi-Tenant)** | **Private (Tenant-Isolated or Self-Hosted)** |
|——–|—————————-|———————————————|
| **Deployment** | Vendor-hosted API (e.g., OpenAI, Anthropic, Google) | Deployed in your own VPC/on-prem or managed single-tenant |
| **Speed to Value** | Instant via SaaS APIs | Longer setup, more MLOps |
| **Data Residency** | Vendor-controlled, regional options available | You choose exact data region |
| **IP Control** | Vendor promises “no training on your data” | Full control and verifiable segregation |
| **GDPR Impact** | Requires DPA/SCCs and audit of subprocessors | Simplifies DPIA; minimal transfers |
| **Cost Model** | Usage-based | Higher fixed compute/storage |
| **Use Case Fit** | Low-sensitivity content (marketing, taxonomy, code helpers) | Sensitive workflows (contracts, supplier data, pricing, PII) |
GDPR and IP Protection Guidance
– Public LLMs: Ensure vendor provides a signed DPA, transparent subprocessor list, no-training guarantees, and regional processing (EU-only endpoints where possible).
– Private LLMs: Control inference and logs within your perimeter, using your own KMS and encryption policies. This enables full compliance with Articles 28–32 of GDPR and reduces DPIA risk.
– Hybrid Approach: Many enterprises route prompts dynamically—sending sensitive queries to private models while using public APIs for low-risk, high-IQ tasks like taxonomy generation or copywriting.
For B2B environments, the optimal setup is typically hybrid:
– Use private or open-weights LLMs (Llama, Mistral) for sensitive or regulated data such as supplier contracts, pricing sheets, and technical drawings.
– Use public LLMs (GPT-4.1, Claude, Gemini) for low-risk, content-generation workflows such as product copy, taxonomy mapping, and SEO metadata.
– Implement a model gateway within your PIM that handles prompt routing, PII redaction, and audit logging.
– Conduct a DPIA and document all retention and data-transfer policies to stay compliant with GDPR and enterprise security mandates.
By balancing capability, governance, and cost, enterprises can confidently adopt AI that enhances productivity while preserving brand trust and regulatory compliance.